Zeitplan-bewusstes Alerting
Teilen Sie uns mit, wann ein Job ausgeführt werden soll. Wenn der Ping nicht innerhalb des Kulanzfensters eintrifft, wird automatisch ein Incident eröffnet.
Heartbeat- & Dead-Man's-Switch-Monitoring für jeden geplanten Task — Cron Jobs, ETL-Pipelines, Backups und Queue-Worker. Wenn ein Durchlauf zu spät ist, ausbleibt oder mit einem Fehlercode endet, erfährt Ihr Team es noch vor den Daten.
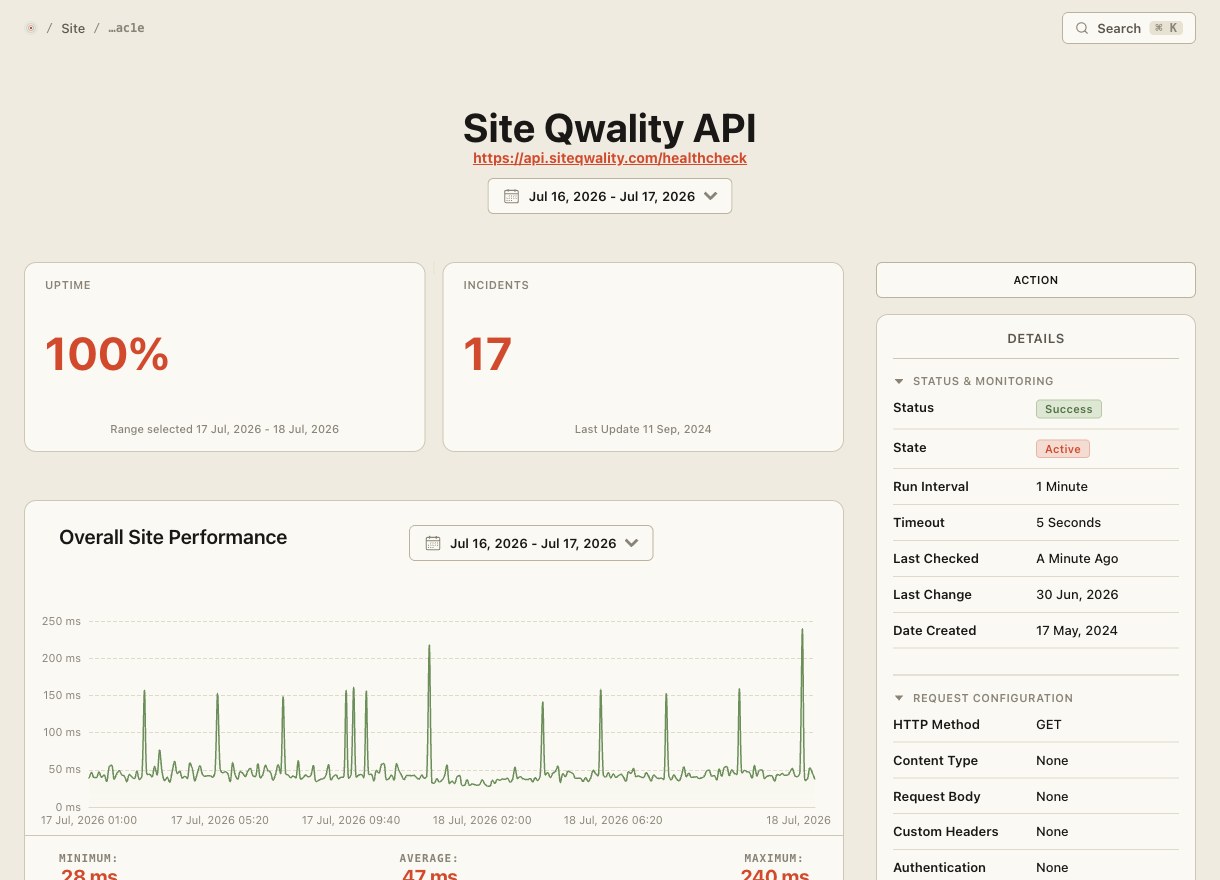
Uptime-Checks funktionieren durch HTTP-Anfragen. Geplante Jobs funktionieren umgekehrt — sie melden sich, wenn sie erfolgreich sind. Site Qwality gibt jedem Job eine eindeutige Ping-URL; Stille bedeutet, dass etwas schiefgelaufen ist.
Teilen Sie uns mit, wann ein Job ausgeführt werden soll. Wenn der Ping nicht innerhalb des Kulanzfensters eintrifft, wird automatisch ein Incident eröffnet.
Fügen Sie nach der geplanten Zeit einen konfigurierbaren Puffer hinzu, bevor ein Alert ausgelöst wird — um Queue-Tiefenvarianz auszugleichen, ohne echte Ausfälle zu verpassen.
Übergeben Sie den Exit-Code und die Laufzeit Ihres Jobs an die Ping-URL. Alert bei Nicht-Null-Exits oder Läufen, die eine erwartete Höchstdauer überschreiten.
Separate Alert-Typen für Jobs, die nie starten, und Jobs, die starten aber nicht abschließen — damit die Fehlersuche mit dem richtigen Kontext beginnt.
Ein einfaches HTTPS GET oder POST an eine URL ohne SDK-Anforderung. Funktioniert von Bash, Python, Node, Ruby, Go — überall, wo Sie eine Anfrage stellen können.
Eine Zeitleiste jedes Pings, jeder Laufzeit und jedes Exit-Codes, damit Sie sich schleichend verlängernde Laufzeiten erkennen, bevor sie zu verpassten Fenstern werden.
Traditionelles Monitoring prüft, ob Ihr Service antwortet. Cron-Monitoring kehrt das um — Ihr Job signalisiert bei jedem Lauf Erfolg. Ein ausgebliebenes Signal ist selbst der Alert. Kein Polling, kein Log-Scraping, kein Agent zum Pflegen.
Kein SDK, kein Daemon, keine Konfigurationsdatei. Kopieren Sie die Ping-URL aus Ihrem Dashboard und fügen Sie einen curl-Aufruf an Ihr bestehendes Skript an. Die Exit-Code- und Laufzeit-Parameter sind optional — fügen Sie sie hinzu, wenn Sie detailliertere Alerts wünschen.
Zeile Code, um jeden geplanten Job zu integrieren
typische Zeit vom verpassten Ping bis zur Alert-Zustellung
Ausführungsverlauf für Trendanalysen gespeichert
kostenloser Tarif — ohne Kreditkarte starten
Jeder Monitor erhält eine eindeutige Ping-URL. Ihr Job ruft diese URL auf, wenn er erfolgreich abgeschlossen wird. Wenn der Ping nicht innerhalb des erwarteten Fensters plus Kulanzfenster eintrifft, eröffnet Site Qwality einen Incident und benachrichtigt Ihr Team.
Legen Sie ein Kulanzfenster fest — ein Pufferfenster nach der geplanten Zeit, bevor ein Alert ausgelöst wird. Für Jobs mit variabler Laufzeit können Sie auch einen maximalen Laufzeit-Schwellenwert festlegen, damit Sie über zu lang laufende Durchläufe informiert werden.
Ja. Hängen Sie ?exit=\$? an die Ping-URL an, um den Exit-Code aufzuzeichnen, und ?duration= für verstrichene Sekunden. Nicht-Null-Exits lösen einen eigenen Alert-Typ aus, damit Sie wissen, ob ein Job nie gestartet wurde oder gestartet ist und dann fehlgeschlagen ist.
Nein. Die Integration ist eine einzige HTTPS-Anfrage — ein curl-Befehl, ein fetch()-Aufruf oder das Äquivalent in einer beliebigen Sprache. Kein Daemon, kein Agent, keine Code-Abhängigkeit zum Pflegen.
Ja — Zeitpläne können auf jedes Intervall ab jeder Minute eingestellt werden. Der erwartete Zeitplan verwendet Standard-CRON-Syntax, damit Sie jede Kadenz präzise ausdrücken können.
Uptime, Cron, Synthetic, Logs, RUM, Incidents und Statusseiten. Kostenlose Stufe bei jedem Produkt.