Logische Service-Gruppierung
Fassen Sie Monitore zu benannten Services zusammen — Zahlungs-API, Checkout-Flow, Authentifizierung — damit Ihr Team in Services denkt, nicht in einzelnen URLs und Ports.
Ein aktuelles Verzeichnis aller Services Ihres Teams: aktueller Verantwortlicher, wer jetzt gerade Rufbereitschaft hat, vorgelagerte Abhängigkeiten, Links zu Dashboards und Runbooks sowie den Gesundheitsstatus auf einen Blick — alles an einem Ort.
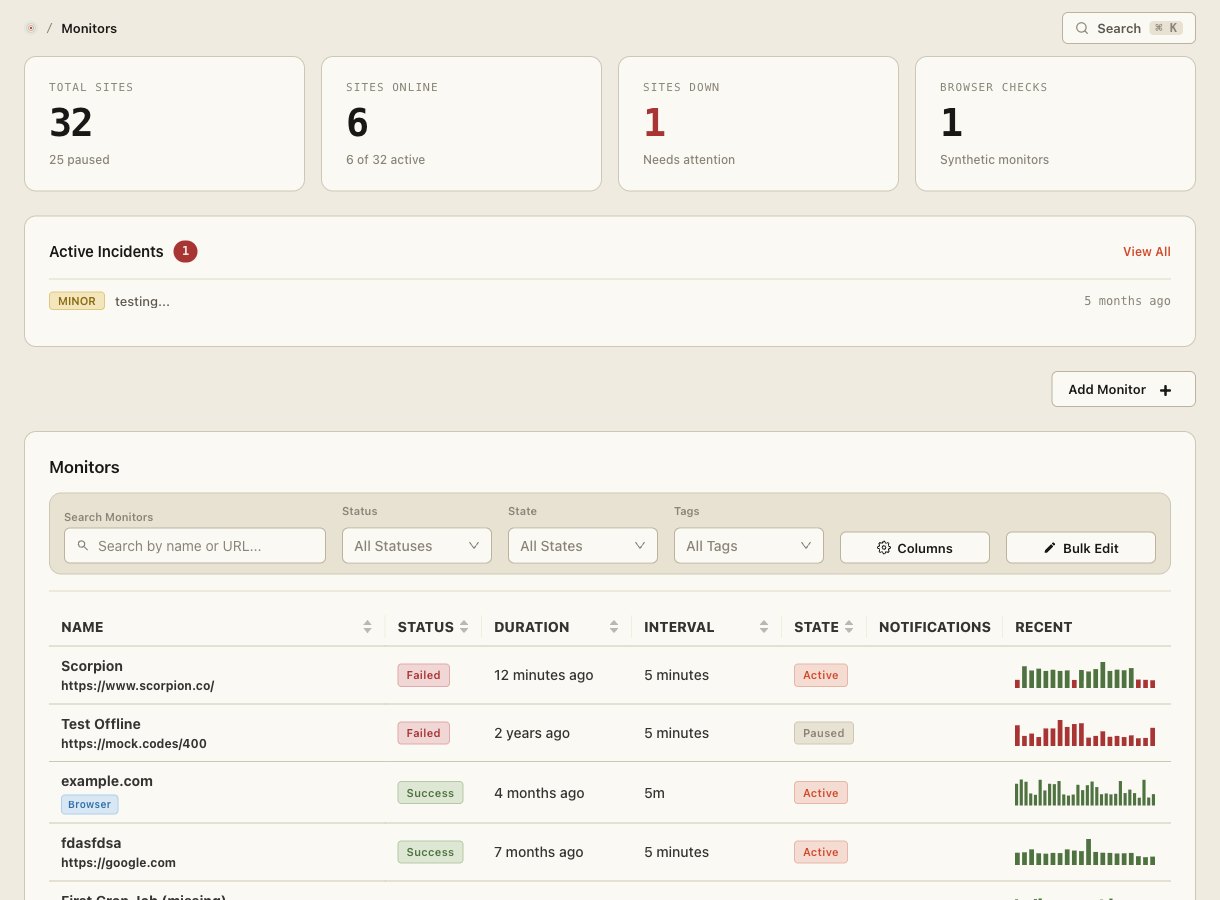
Der Service-Katalog ist die maßgebliche Antwort auf Fragen nach Zuständigkeit, Rufbereitschaft, Abhängigkeiten und aktuellem Gesundheitsstatus jedes Services in Ihrem Stack. Er verbindet Ihre Monitore, Incidents, Eskalationsrichtlinien und Runbooks zu einer einzigen übersichtlichen Ansicht.
Fassen Sie Monitore zu benannten Services zusammen — Zahlungs-API, Checkout-Flow, Authentifizierung — damit Ihr Team in Services denkt, nicht in einzelnen URLs und Ports.
Jeder Service hat ein Eigentümer-Team und einen verknüpften Rufbereitschaftsplan. Eine einzige Seite zeigt, wer verantwortlich ist und wen Sie jetzt kontaktieren müssen — kein Suchen in Slack.
Erfassen Sie vor- und nachgelagerte Abhängigkeiten, damit Responder beim Ausfall eines Services sofort den Blast-Radius verstehen. Kein mühsames Recherchieren mehr, was von was abhängt.
Verknüpfen Sie Runbooks, Dashboards, Code-Repositories und Wikis direkt mit einem Service. Alles, was ein Responder bei einem aktiven Incident benötigt, ist einen Klick entfernt.
Incidents, die für einen Service erstellt werden, werden automatisch über die Eskalationsrichtlinie des Services geleitet — ohne manuelle Zuweisung. Das richtige Team wird jedes Mal benachrichtigt.
Verknüpfen Sie einen Service mit einer Komponente auf Ihrer öffentlichen Statusseite. Wenn ein Incident erstellt wird, aktualisiert sich der Komponentenstatus automatisch, sodass Ihre Nutzer ohne zusätzlichen Aufwand informiert bleiben.
Die Katalog-Startseite zeigt den aktuellen Zustand jedes Services — grün, beeinträchtigt oder ausgefallen — abgeleitet aus Live-Monitor-Daten. Beim Incident ist dies der erste Bildschirm, den Ihr Team öffnet, um Umfang und Auswirkungen zu verstehen, bevor es tiefer eintaucht.
Definieren Sie Services, Eigentümer, Abhängigkeiten und Richtlinien-Zuweisungen über die REST API. Legen Sie die Aufrufe in ein Script, das Ihr Repository verwaltet, und Änderungen durchlaufen Ihren normalen Pull-Request-Prozess — überprüft, freigegeben, angewendet — damit niemand den Katalog manuell in einer UI bearbeitet.
Ort für Verantwortlichen, Rufbereitschaft und Status jedes Services
manuelle Schritte, um einen Incident an das richtige Team zu leiten
sichtbare Abhängigkeits-Ebenen pro Service-Karte
kostenloser Tarif — Service-Katalog von Anfang an inklusive
Ein Service ist eine benannte logische Einheit, die einen oder mehrere Monitore bündelt, einen Eigentümer trägt, mit einer Eskalationsrichtlinie und einem Rufbereitschaftsplan verknüpft ist und optional einer Statusseiten-Komponente zugeordnet wird. So denkt Ihr Team über Ihre Infrastruktur nach — nicht wie sie physisch aufgebaut ist.
Der Gesundheitsstatus wird aus den mit dem Service verknüpften Monitoren abgeleitet. Schlägt ein Monitor an, wird der Service als beeinträchtigt oder ausgefallen angezeigt. Anzahl und Schweregrad offener Incidents werden zusammen mit dem monitor-basierten Gesundheitssignal dargestellt.
Ja. Sie können vor- und nachgelagerte Abhängigkeiten für jeden Service festlegen. Bei einem Incident zeigt die Service-Detailseite, ob auch Abhängigkeiten beeinträchtigt sind, was Respondern hilft, den Blast-Radius sofort zu verstehen.
Ja. Verknüpfen Sie einen Service mit einer Komponente auf Ihrer öffentlichen Statusseite. Wenn ein Incident für den Service ausgerufen wird, aktualisiert sich der Komponentenstatus automatisch, und wenn der Incident gelöst ist, kehrt die Komponente zu „In Betrieb" zurück.
Ja — jedes Katalog-Feld (Eigentümer, Eskalationsrichtlinie, Rufbereitschaftsplan, Runbook-URL, Abhängigkeits-Links) ist über die REST API konfigurierbar. Legen Sie die JSON-Definitionen in Ihr Repository, und Ihr Standard-Pull-Request-Review wendet sie an.
Uptime, Cron, Synthetic, Logs, RUM, Incidents und Statusseiten. Kostenlose Stufe bei jedem Produkt.